

朝倉書店の『アンケートデータ分析: 選択式回答のテキストマイニング流分析』を読了したので、書評含め紹介します。

読みたいと思った理由
テキストマイニングは「自由記述回答に使うもの」という固定観念を壊しに来るタイトルがとても気になり購入しました(そこまで最初から理解していた訳ではないですが苦笑)。
本書籍のメインディッシュ
例えば、複数回答設問なら「回答者ごとに選ばれた選択肢の表現をカンマ区切りで連結させる」など、言われたら「そうか、それでイケるのか」となるtipsを、調査データの他の代表的な回答形式ごとに披露してくれています。こうしたtipsを見て「簡単じゃないか」と思うのは、典型的な後知恵バイアスだと思います。
少なくとも自分はこの本を読まなければ、一生(テキストマイニングではなく)データマイニング手法で対応していたと思います。それは致命的ではないかもしれませんが、分析者としての成長は止まったままだったと思います。
上手だなぁと思った点
3章で数量化Ⅲ類の出力結果に触れておくことで、この章から本格的に始まる「テキストマイニング流分析」のアウトプットの妥当性を自然な形で伝えてくれているように感じられました。つまり、同じようなことがKH-Coderで全部できてしまうのなら、その方が分析者にとってはラクですし、「このやり方を理解したい」と思わせる流れが上手に仕込まれているように感じました。
本書籍のデザート
本書のメインディシュは、テキストマイニング手法の拡張だと思うのですが、科学的思考の御作法についても要所で触れられている点が良かったです。探索的分析から仮説検証的な分析へと進む流れの徹底や、最終章におけるリサーチクエスチョンの構造化フレームワークPECOの紹介は、分析者がどんな事前仮説をもって調査データの収集と分析に臨むのかを思い出させてくれました。
用語理解
多分ですが、最終章までの分析は、厳密には「探索的な分析」の範疇のものだと思います。この探索的分析の内側で見出された「別途の検証に値するかもしれない仮説」の妥当性を検証する意味で「仮説検証的な分析」が登場していると理解しました。おそらくこの本を読んで分析する初学者の方は、この検証仮説を「a prioriな仮説(事前仮説)」のように装うことはまずないし、決してそうはならないように解説されていると感じました。
分析業務では、探索的分析の内側で実施される仮説検証的な分析(つまり純粋な検証的分析ではない)で得られた知見を元に、例えばメールマーケティングのパーソナライゼーションのA/Bテストなど(純粋な検証的分析)が別途計画されるはずなので、当該知見の一般化に伴うリスクは比較的小さいものだと考えています。
補説
本書籍のマインドマップと、本書籍内容も踏まえ筆者が描いたデータ活用プロセス図の紹介です。
マインドマップ
本書6章は実践テーマを題材に1章から5章の内容を振り返るものだったため、このマインドマップからは外しました。ただ、実践解説だからこそ登場する「心理尺度の解説」や「PECOの紹介」など、科学的思考に不可欠な要素に触れられている点がとても参考になりました。
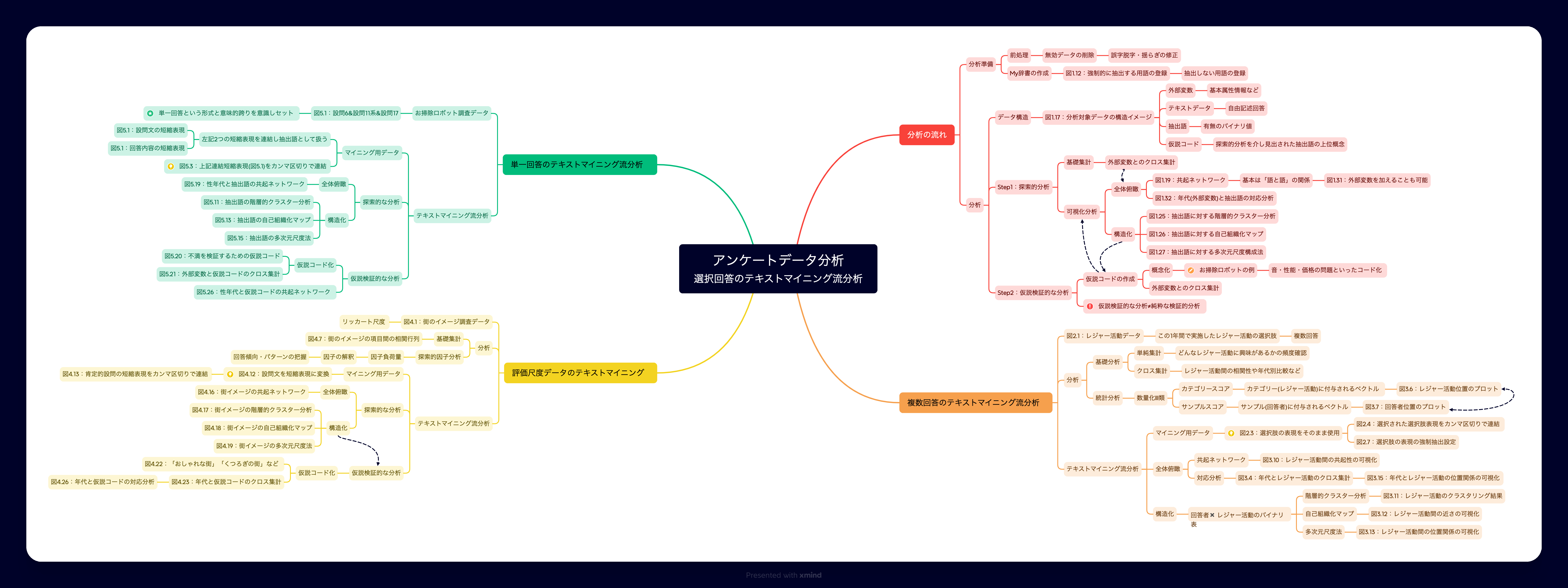
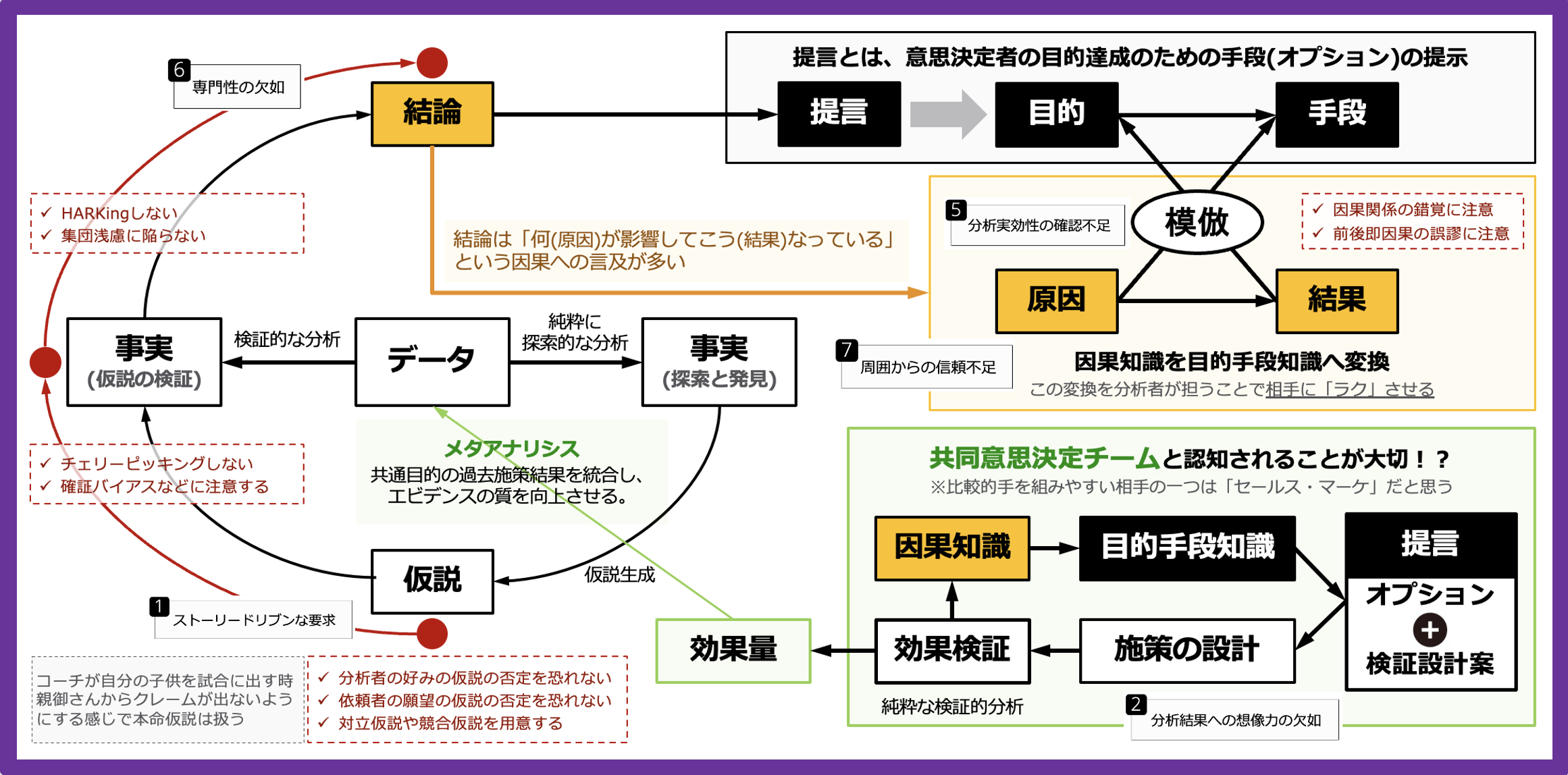
データ活用プロセス
データ分析に関する書籍は、主にこの図左側(分析プロセスの本体)に焦点を当てる訳ですが、分析実務では「分析の後工程」がとても重要です。この後工程で、本格的な効果検証の設計、つまり純粋な検証的分析(確証的分析)が計画されるからです。この図では、分析工程と後工程を要素分解し、両者をメタアナリシスで結びつけました。
最後に
アンケートデータは、実務でも最も身近なデータの一つだと思います。この身近なデータで基礎分析、テキストマイニング(KH-Coderの使い方)、選択式回答に対するテキストマイニング流分析、そして科学的思考について学べるとてもステキな本でした。
以上です!












{kind=link}
Comment