

はじめに
決定木は、古典的な機械学習手法の一つですが、前処理の簡便性や解釈のしやすさ、アンサンブル学習のベース推定器になることなどから人気のアルゴリズムです。本稿では、この決定木の多様な活用法を、高速倹約決定木、最適決定木、サロゲート木を介し紹介します。
高速倹約決定木(Fast-and-Frugal Trees)
高速倹約決定木は、認知心理学領域で探究されてきた意思決定モデルです。このモデルは、例えば消防士や救急医が、限られた情報と時間の中で下す判断の様子を認知心理学の観点から考察し表現したもので、以下のような特徴を持ちます。
- 少数の重要な手がかりを使用し、情報処理の負担を軽減する。
- 状況に応じて手がかりを適応的に選択し、迅速な判断を可能にする。
- 各手がかりに対して単純な判断ルールを適用し、意思決定プロセスを簡略化する。
高速倹約決定木の構造
高速倹約決定木の構造の特徴は、その条件分岐の少なさです。普通の決定木では、あらかじめ設定された分岐条件を満たす限り、ノードは分岐する可能性を持ちますが、高速倹約決定木では、分岐した一方のノードはリーフ、すなわち最終判断ポイントになります。また、木の深さも大抵は3程度で構築され、意思決定プロセスが簡潔に構造化されます。
図1:高速倹約決定木の構造例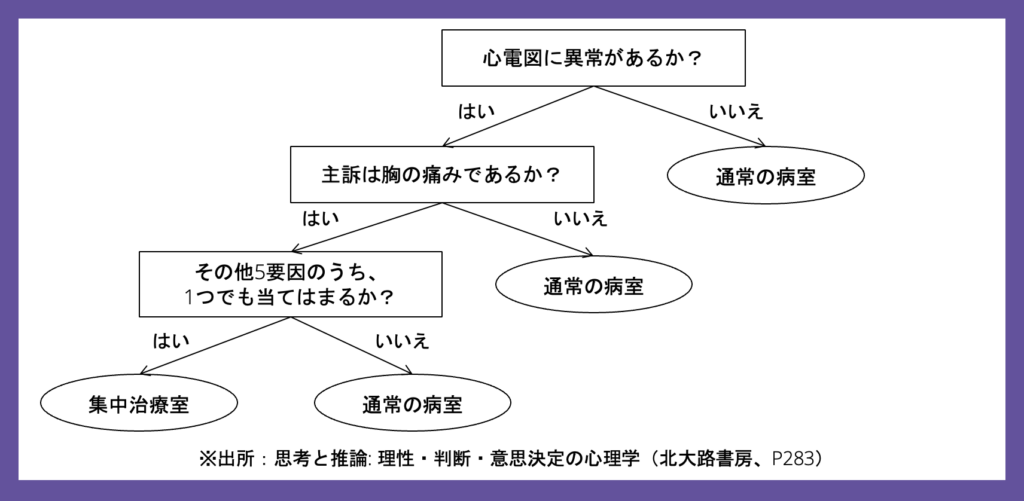
図1は、Green & Mehr(1997)による救急患者への意思決定プロセスの一例です[1]。ノードの分岐ごとに逐次的に判断が下され、最大3回の判断で意思決定が最終化されています。訴訟リスクを恐れる救急医の判断は、保守的な方向(集中治療室)に偏りやすく、経営資源が食い潰されがちです。高速倹約決定木は、このような意思決定バイアスの軽減に役立ち、特に情報と時間に限りのある意思決定環境下で有用とされています。
高速倹約決定木の限界
どのような専門家にも判断に誤りがあるように、高速倹約決定木の出力も完璧ではありません。高速倹約決定木は、少数の重要な手がかりから迅速な判断を可能にしますが、手がかりの選択が適切でなければ判断の精度は低下します。また、環境変化に合わせた手がかりの更新も必要になるでしょう。
最適決定木(Optimal Decision Trees)
一般的な決定木の構造は、現実的な計算時間で処理するため貪欲的に探索され、局所的に最適なものの組合せで決められています。ところが、近年のソルバー技術の進歩と計算機能力の向上によって、木の深さを限定すれば、ノードの分割条件をすべて考慮し全体最適な構造を特定できるようになりました。このように構築されたものが最適決定木です。
👍 汎化性能:貪欲的に訓練された通常の決定木よりも汎化性能が優れている傾向
👎 計算コスト:大規模なデータや高次元特徴量では計算時間が増大
最適決定木の構築
最適決定木の構築には、専用のライブラリを使う必要があります。本稿では、ルーヴァン・カトリック大学の人工知能研究チームによって開発されたPyDL8.5による構築例を紹介します[2]。このライブラリは、特徴量も正解ラベルもバイナリの分類タスクに特化している点にはご留意ください。
まず、比較対象となる一般的な決定木を構築し、その構造を確認します。利用データは、PyDL8.5のGithubページに公開されているデータanneal.txtを使います[3]。カラムC1からC93の特徴量と正解データC0はすべて2値で、812サンプル中625サンプルの正解ラベルが1のデータで、各特徴量に関する説明は提供されていません。
以下の通り、必要ライブラリをインポートしておきます。
# import library
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.tree import DecisionTreeClassifier
from pydl85 import DL85Classifier # 最適決定木
from sklearn.ensemble import HistGradientBoostingClassifier
import graphviz
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree利用データを読み込み、訓練データと検証データに分割します。
# import modeling dataset
dataset = pd.read_csv('./data/anneal.txt', delimiter=' ', header=None)
dataset.columns = dataset.columns.map(lambda x:'C'+str(x))
print(dataset.shape)
display(dataset.head())
# set the variable role
X = dataset.loc[:,'C1':]
y = dataset.loc[:,'C0']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=0)
print(y.describe(), y.sum())データは、PyDL8.5が扱える(特徴量も正解ラベルも)2値データとなっています。 最適決定木との比較のため、通常の決定木を、sklearnを用いて構築します。
最適決定木との比較のため、通常の決定木を、sklearnを用いて構築します。
# train a general decision tree
dt = DecisionTreeClassifier(max_depth=3, random_state=0)
dt.fit(X_train, y_train)
# validate the model
y_pred_train = dt.predict(X_train)
y_pred_test = dt.predict(X_test)
print("Confusion Matrix on training set below\n", confusion_matrix(y_train, y_pred_train))
print("Confusion Matrix on test set below\n", confusion_matrix(y_test, y_pred_test))
print("F1 Score on training set =", round(f1_score(y_train, y_pred_train), 4))
print("F1 Score on test set =", round(f1_score(y_test, y_pred_test), 4))
# plot the tree
plt.figure(figsize=(12, 5))
plot_tree(dt, filled=True, feature_names=X_train.columns)通常の決定木は、訓練データのリサンプリングや学習時のrandom_stateの値で変化しやすいと知っていても、深さ3までに登場しない特徴量に対して、強い関心を持ちにくいのではないでしょうか。ここでは、以下の図2に登場する特徴量群が、最適決定木ではどうなるかの確認へと進みます。
図2:通常の決定木の構造例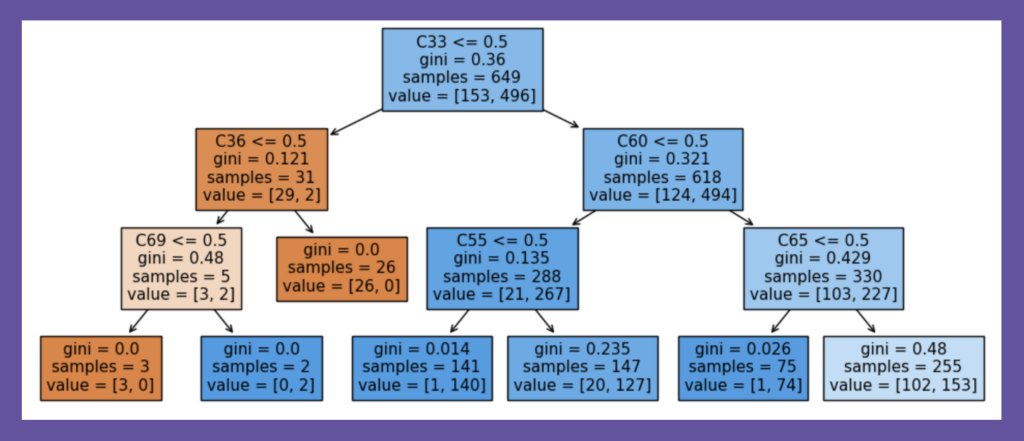
PyDL8.5を使った最適決定木も、深さを3で構築します。
# train an optimal decision tree
odt = DL85Classifier(max_depth=3, min_sup=5)
odt.fit(X_train, y_train)
# model the validation
y_pred_train = odt.predict(X_train)
y_pred_test = odt.predict(X_test)
print("Confusion Matrix on training set below\n", confusion_matrix(y_train, y_pred_train))
print("Confusion Matrix on test set below\n", confusion_matrix(y_test, y_pred_test))
print("\nF1 Score on training set =", round(f1_score(y_train, y_pred_train), 4))
print("F1 Score on test set =", round(f1_score(y_test, y_pred_test), 4))
# print the tree
print("\nSerialized json tree:", odt.tree_)
dot = odt.export_graphviz()
graph = graphviz.Source(dot, format="png")
graph上記コード内のmin_supは、決定木のリーフ(子ノードを持たないノード)の最小サンプル数です。特定の制約条件下で最適構造を探索するのは、一般的な最適化問題と同じです。sklearnのようにrandom_sateがないのは、グローバルに最適な構造を探索し決定しているためで、最適決定木の探索にサイコロを振る必要がないからです。今回の最適決定木は、以下のような構造になります。
図3:最適決定木の構造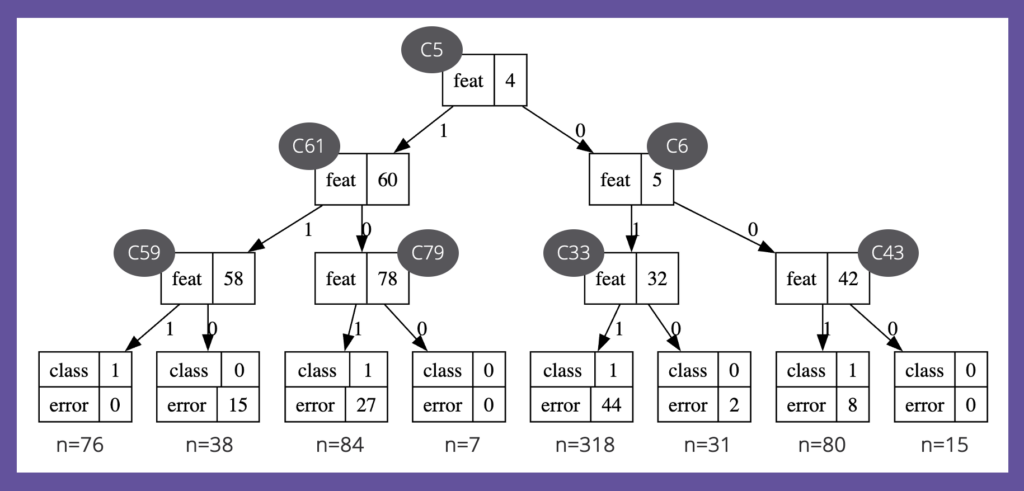
PyDL8.5の最適決定木の表示機能は限定的なため、特徴量の名前とリーフのサンプル数は筆者が追記しました。決定木の解釈時には最初の分岐条件に目が向きますが、今回の木では、特徴量C5がその位置にあります。先の通常の決定木では、この特徴量C5は深さ3まで見ても登場しないことを確認して下さい。
通常の決定木は、データ解釈を助けてくれますが、果たしてその助けが有益と言えるのか、このような結果を見ると不安になるでしょう。決定木を使った解釈では、常に謙虚であれと言われる理由がここにあります(注釈:訓練データと検証データをランダムに分割するシード値を0から1や2などへ変更しても、最適決定木の構造は変わりませんでした)。
参考:ランダムフォレストの変数重要度
決定木は、学習データのリサンプリングによっても形を変えやすいため、どの特徴量が構造的に重要かを判断する際には、アンサンブル学習(ランダムフォレストなど)を用いるのが普通です。今回の変数重要度を調べると、特徴量C5は重要度順位が24位でした。なかなか注目し難い順位ですが、最適決定木ではこの特徴量が構造決定に役立っています。
図4:ランダムフォレストに基づく変数重要度トップ30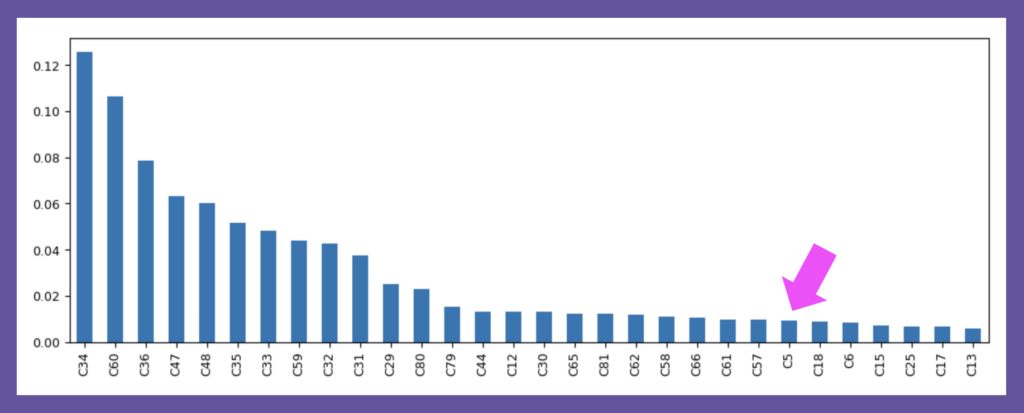
サロゲート木(Global Surrogate Tree)
本稿で、サロゲート木と呼んでいるものは、厳密には「決定木ベースのグローバル・サロゲート・モデル」と呼ばれます[4]。グローバル・サロゲート・モデルとは、複雑で解釈困難なブラックボックスモデル(DNNや勾配ブースティング木など)を、解釈のしやすいモデルで代替したものです。この解釈しやすいモデルとして、線形回帰モデルや決定木が選ばれます。例えば、CatBoostなどで構築された複雑でブラックボックスなモデルを、sklearnの決定木で再構築します。サロゲートモデルを構築する流れは、以下の通りです[4]。

- 解釈性:複雑なアンサンブル木を簡素化し、理解しやすくする。
- 構築性:最適決定木のような専門ライブラリを使うことなく構築できる。
サロゲート木の構築コード
勾配ブースティング木のサロゲート・モデルを構築します。勾配ブースティング木は、sklearnのHistGradientBoostingClassifierクラスを用い、木の深さは3とします。サロゲート木は、この勾配ブースティング木の予測値y_pred_trainを使って訓練します[5]。
# train the black-box model
hgbc = HistGradientBoostingClassifier(max_depth=3, random_state=0)
hgbc.fit(X_train, y_train)
# original model validation
y_pred_train = hgbc.predict(X_train)
# train the global surrogate model
gsm = DecisionTreeClassifier(max_depth=3, random_state=0)
# gsm = DecisionTreeClassifier(max_depth=4, random_state=2) #深さ4のサロゲートモデルはここを実行
gsm.fit(X_train, y_pred_train)サロゲート木の構築は簡単ですが、元モデルを完全に再現することは容易ではありません。今回のケースでは、元モデルとサロゲート・モデル間の不一致件数は74件で、F1スコアは0.9254です。サロゲート・モデルの役割は、ブラックボックス・モデルの再現なので、0.95くらいを目指して、もう少し深い木にしても良いかもしれません。
# colleration between the original model and the surrogate model
print('colleration between the original model and the surrogate model')
print("F1 Score =", round(f1_score(hgbc.predict(X_train), gsm.predict(X_train)),4))
print("Confusion Matrix\n", confusion_matrix(hgbc.predict(X_train), gsm.predict(X_train)))
# colleration between the original model and the surrogate model
# F1 Score = 0.9254
# Confusion Matrix
# [[116 19]
# [ 55 459]]続けて、サロゲート木の構造を確認します。勾配ブースティング木は、通常の決定木よりも高性能を期待できるため、その構造は気になるところでしょう。
図5:勾配ブースティングモデルのサロゲート・モデル(深さ3、F1スコア:0.9254)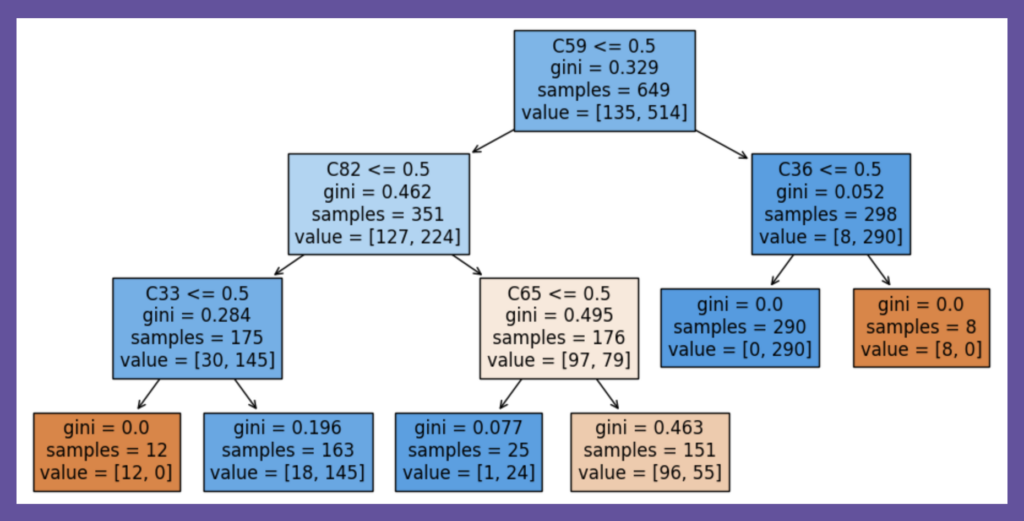
上の図5の通り、サロゲート木は、これまで見てきたどの決定木とも違った形をしています。参考までに元モデルはそのままに、サロゲート木の深さを4とした場合の結果を、以下の図6に掲載します。偶然でしょうが、ようやくここで最適決定木の第一分岐条件であった特徴量C5が登場します。
図6:勾配ブースティングモデルのサロゲート・モデル(深さ4、F1スコア:0.9468)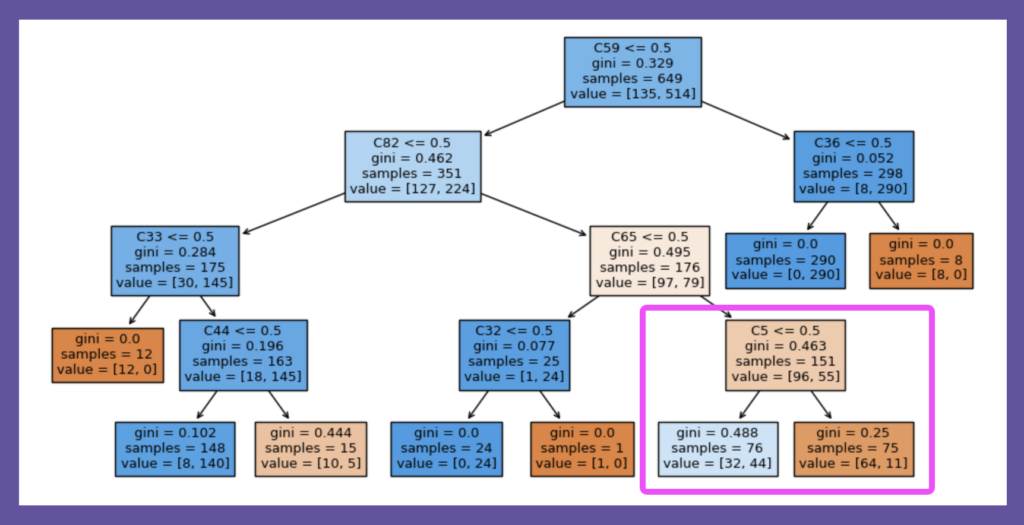
各種決定木の使い所
これまで見てきた通り、決定木は簡便さと解釈のしやすさから人気のアルゴリズムですが、同じデータに対しても多様な姿を表し、その使い方には整理が必要そうです。最後に、この点について考察してみましょう。
高速倹約決定木
限られた情報から(ある程度)正確で即時の判断を繰り返し求めらるタスクには、高速倹約決定木の活用を検討しましょう。この木はシンプルなため、判断精度を向上させたい場合には、新しい「手がかり情報」の獲得を目指しましょう。例えば、人材採用やプロジェクトアサインメントに際しては、勘や属人的判断ではなく構造化面接や構造化スコアを使って手がかり情報を入手し、それに基づく高速倹約決定木を構築し直すということです。高速倹約決定木の構築には、RパッケージのFFTreesが使えるので[6]、身の回りの意思決定タスクで試してみると良いでしょう。
最適決定木
木構造を全体最適化できる強みを活かし、探索的分析の補助ツールとして使えると思います。通常の決定木は、学習時のランダムシード値の変化によっても形を変えやすく、解釈性に一抹の不安を残します。その点、グローバルに最適な構造を決定してくれる最適決定木は安心です。ただ、最適決定木であっても過学習の課題を残しています。本稿では取り上げませんが、内的検証、テンポラル検証、外的検証の違いを理解し[7]、過学習モデルの解釈に陥らないように注意することが大切です。
最適決定木は、より一般的には、機械学習と最適化の融合文脈で注目される技術です。より詳しくは、以下、東京海洋大学久保幹雄教授による「数理最適化と機械学習の融合』に関する動画を参照ください。
サロゲート木
複雑な勾配ブースティング木などのブラックボックスモデルの用途の多くは予測(prediction)だと思います。あるインスタンスに対する予測値の解釈は、SHAPやLIME(ローカル・サロゲートモデルと呼ばれます)によって得られますし[4]、重要変数と正解データのクロス集計によって簡便的に解釈されることも少なくありません。サロゲート木は、分析の非専門家向けに、予測モデルの出力傾向を俯瞰的に説明する用途に限定して使うと良いでしょう。
まとめ

Reference
[1] https://pubmed.ncbi.nlm.nih.gov/9300001
[2] https://pydl85.readthedocs.io/en/latest/index.html
[3] https://github.com/aia-uclouvain/pydl8.5/tree/master/datasets
[4] https://christophm.github.io/interpretable-ml-book/global.html#theory-4
[5] https://towardsdatascience.com/explainable-ai-xai-with-a-decision-tree-960d60b240bd
[6] https://github.com/ndphillips/FFTrees
[7] https://academic.oup.com/ckj/article/14/1/49/6000246











{kind=link}
Comment